Most Overlooked Variable Length Error for SAS CDISC Data
The FDA review of an electronic submission requires the merging of submitted data to confirm that the source produces the same aggregate results of the submitted summary analysis. This can only be accomplished if there are clearly defined keys between the datasets and that the keys have standard attributes. A common error that would occur is that the length of the key fields is slightly different. For example, the study identifier (STUDYID) of one set of data is set to length of 7 and another is set to 10. When the two sets are merged, some of the variable values will be truncated leading to errors. An evaluation if key field lengths are crucial in standardizing the key field lengths.
CDISC standards are very helpful in getting the variable attributes such as names and labels standardized. It however, does not enforce the standards of lengths leaving it up to you to evaluate and come up with the correct length for each study submitted. The following steps are recommended to standard your key field lengths to avoid truncation errors.
Step 1
Identify all datasets within all your studies being submitted that contains the same variables. An example is that you are submitting three studies and each study has about 15 datasets. In this case, there are common variables such as STUDYID, DOMAIN, USBJID that are in more than one dataset. If any variable that exist in more than one dataset, they should be included in this analysis.
Step 2
Determine the longest character length value of each variable across all datasets. So for example, if your verbatim variable AETERM has a text value with the longest length of 45 characters on one dataset and 59 characters on another, you would note the 59. The goal is to evaluate all the data values and determine the longest length across all your data.
Step 3
Set the maximum length that will be the standard across all dataset. In the above example, you can set the maximum to be 59 but it may be a better standard to round the length so 60 would be a better standard. In this case, all variables AETERM across all your studies will be set to 60.
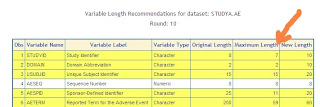
An example report shown above illustrates all the variables across three studies. This report is produced by a macro %varlen that automate the evaluation and assignment of the variable lengths. The standardization will prevent errors in your merging of keys but it can also significantly reduce the size of your SAS datasets. Without performing this evaluation, you may just set the variable to be the maximum length of 200 characters. In that case, SAS allocates this and creates very large datasets even though your data values never reach this length. Your standardization effort will result in efficient smaller datasets and allows FDA reviewers using tools such as JMP among other software without causing errors.
CDISC standards are very helpful in getting the variable attributes such as names and labels standardized. It however, does not enforce the standards of lengths leaving it up to you to evaluate and come up with the correct length for each study submitted. The following steps are recommended to standard your key field lengths to avoid truncation errors.
Step 1
Identify all datasets within all your studies being submitted that contains the same variables. An example is that you are submitting three studies and each study has about 15 datasets. In this case, there are common variables such as STUDYID, DOMAIN, USBJID that are in more than one dataset. If any variable that exist in more than one dataset, they should be included in this analysis.
Step 2
Determine the longest character length value of each variable across all datasets. So for example, if your verbatim variable AETERM has a text value with the longest length of 45 characters on one dataset and 59 characters on another, you would note the 59. The goal is to evaluate all the data values and determine the longest length across all your data.
Step 3
Set the maximum length that will be the standard across all dataset. In the above example, you can set the maximum to be 59 but it may be a better standard to round the length so 60 would be a better standard. In this case, all variables AETERM across all your studies will be set to 60.
An example report shown above illustrates all the variables across three studies. This report is produced by a macro %varlen that automate the evaluation and assignment of the variable lengths. The standardization will prevent errors in your merging of keys but it can also significantly reduce the size of your SAS datasets. Without performing this evaluation, you may just set the variable to be the maximum length of 200 characters. In that case, SAS allocates this and creates very large datasets even though your data values never reach this length. Your standardization effort will result in efficient smaller datasets and allows FDA reviewers using tools such as JMP among other software without causing errors.


Comments
Post a Comment